|
I'm a tenure-track Assistant Professor at Wangxuan Institute of Computer Technology, Peking University, where I mainly work on Computational Photography and 3D Vision. I am also affiliated in the Visual Computing and Learning Lab, collaborating closely with Prof. Baoquan Chen, Prof. Libin Liu, Prof. Mengyu Chu, and Prof. Pengshuai Wang. Before joining Peking University, I was a research scientist at NVIDIA Toronto AI Lab. I earned my Ph.D. from the University of Toronto and received both my Master's and Bachelor's degrees from Shandong University. I am always actively recruiting Ph.D. students and research interns! Feel free to drop me a line with your CV and research statement! Email / CV / Google Scholar / LinkedIn |

|
|
My research focuses on Computational Photography and 3D Vision. My goal is to integrate 3D Sensing with World Models to enable intelligent agents to perceive, simulate, and interact with the physical world. |
|
[2025.12] One paper accepted
to
TMLR. We
solve the mode collapse problem by replacing KL with SIM loss.
[2025.12] One paper accepted
to
TIP.
We tackle the challenging blind inverse problems with latent diffusion priors.
[2025.08] One paper accepted to SIGGRAPH
Asia 2025. We developed a
powerful structured light 3D imaging technique achieving 10x accuracy
improvement over traditional methods.
[ more... ]
|
|
I am actively recruiting Ph.D. students (2027 intake) and Research Interns (longer than 3 months). If you are interested, please send your CV and transcript to wenzhengchen@pku.edu.cn. (实验室非常欢迎校内外本科生、研究生同学来前来实习或访问,请感兴趣的同学直接和我联系。) |
|
Full publication list in Google Scholar. |

|
Jiaheng Li*, Qiyu Dai*, Lihan Li, Praneeth Chakravarthula, He Sun, Baoquan Chen#, Wenzheng Chen# SIGGRAPH Asia, 2025 project page / arXiv / code / bibtex Neural single-shot Structured Light (NSL) achieves robust and high-fidelity 3D reconstruction from a single-shot structured light input. |
|
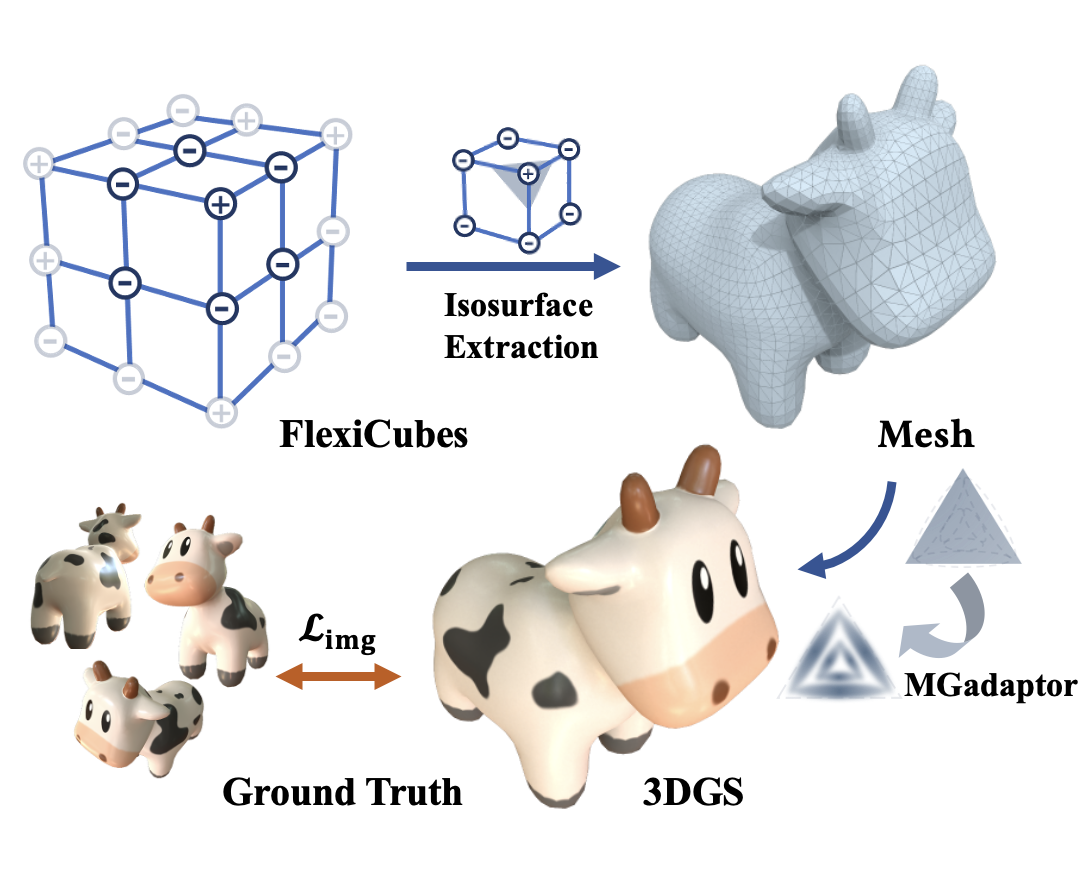
Kai Ye*, Chong Gao*, Guanbin Li, Wenzheng Chen#, Baoquan Chen# ICCV, 2025 project page / arXiv / code (coming soon) / bibtex GeoSplatting introduces a novel hybrid representation that grounds 3DGS with isosurfacing to provide accurate geometry and normals for high-fidelity inverse rendering. |

|
Qiyu Dai*, Xingyu Ni*, Qianfan Shen, Wenzheng Chen#, Baoquan Chen#, Mengyu Chu# CVPR, 2025 project page / arXiv / code (coming soon) / video / bibtex RainyGS integrates physics simulation with 3DGS to efficiently generate photorealistic, physically accurate, and controllable dynamic rain effects for in-the-wild scenes. |
|
Yifei Wang*, Weimin Bai*, Wenzheng Chen, He Sun (* Equal contribution) NeurIPS, 2024 project page / arXiv / code / bibtex EMDiffusion learns a clean diffusion model from corrupted data. |

|
Parsa Mirdehghan, Maxx Wu, Wenzheng Chen, David B. Lindell, Kiriakos N. Kutulakos CVPR, 2024 project page / paper / video / code (coming soon) / bibtex TurboSL provides sub-pixel-accurate surfaces and normals at mega-pixel resolution from structured light images, captured at fractions of a second. |

|
Yuanxing Duan*, Fangyin Wei*, Qiyu Dai, Yuhang He, Wenzheng Chen#, Baoquan Chen# (* Equal contribution, # joint corresponding authors) Proc. SIGGRAPH, 2024 project page / arXiv / code / bibtex |

|
Wenzheng Chen Ph.D. Thesis, 2023
|

|
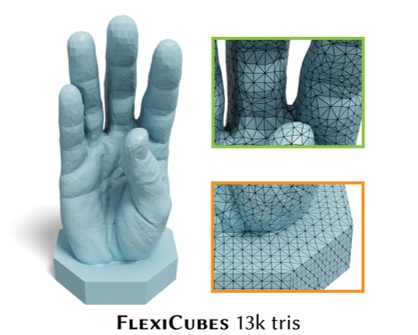
Tianchang Shen, Jacob Munkberg, Jon Hasselgren, Kangxue Yin, Zian Wang, Wenzheng Chen, Zan Gojcic, Sanja Fidler, Nicholas Sharp*, Jun Gao* ACM Transactions on Graphics (SIGGRAPH), 2023 project page / arXiv / code / video / bibtex
|

|
Zian Wang, Tianchang Shen, Jun Gao, Shengyu Huang, Jacob Munkberg, Jon Hasselgren, Zan Gojcic, Wenzheng Chen, Sanja Fidler CVPR, 2023 project page / arXiv / code / video / bibtex Combined with other NVIDIA technology, FEGR is one component of Neural Reconstruction Engine announced in GTC Sept 2022 Keynote. |


|
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, Sanja Fidler NeurIPS, 2022 (Spotlight Presentation) project page / arXiv / code / video / bibtex / Two Minute Paper We develop a 3D generative model to generate meshes with textures, bridging the success in the differentiable surface modeling, differentiable rendering and 2D GANs. |


|
Zian Wang, Wenzheng Chen, David Acuna, Jan Kautz, Sanja Fidler ECCV, 2022 project page / arXiv / code / video / bibtex We propose a hybrid lighting representation to represent spatial-varying lighting for complex outdoor street scenes. |

|
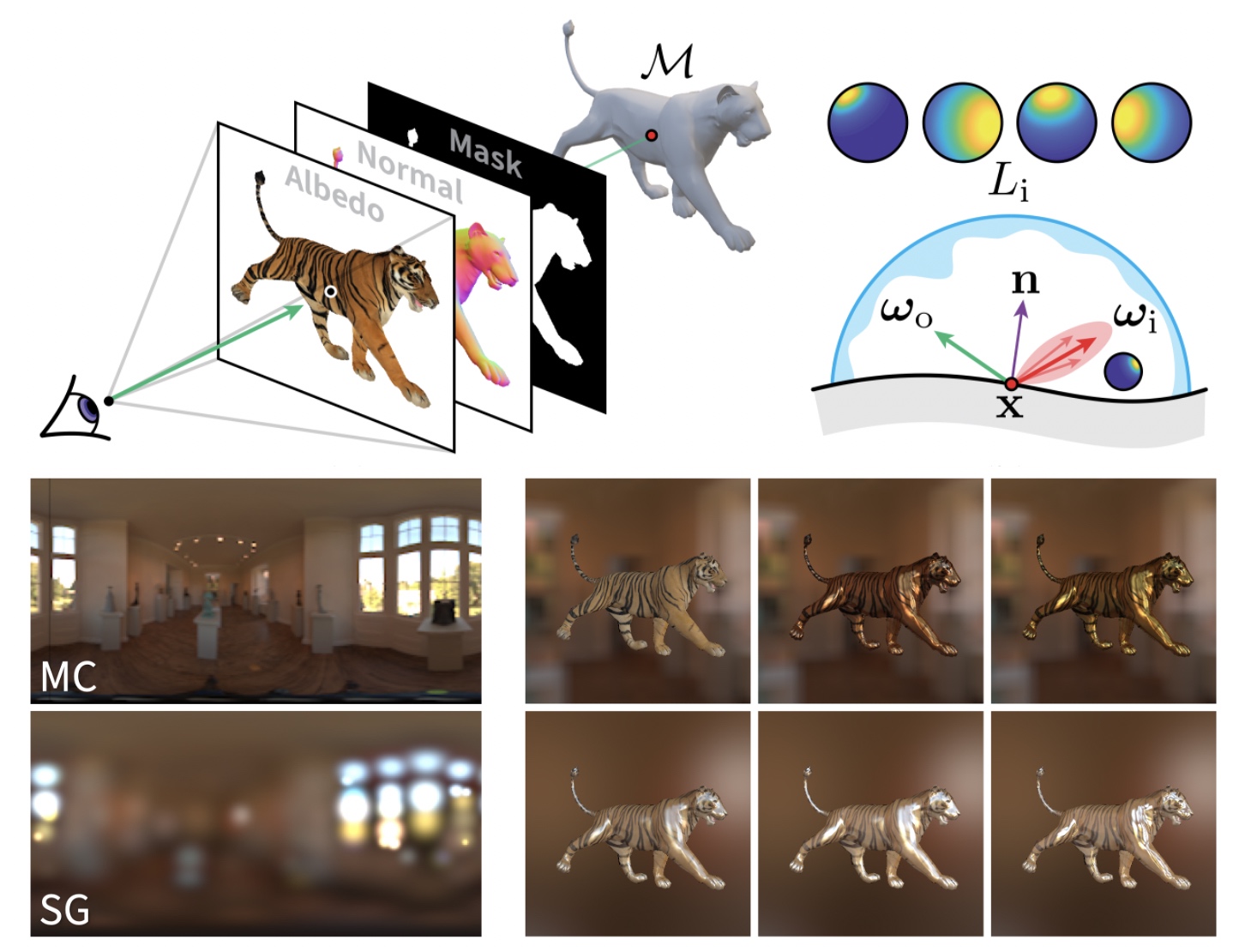
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler CVPR, 2022 (Oral Presentation) project page / arXiv / code / video / bibtex / Two Minute Paper Nvdiffrec reconstructs 3D mesh with materials from multi-view images by combining diff surface modeling with diff renderer. The method supports Nvidia Neural Drivesim |
|
Wenzheng Chen, Joey Litalien, Jun Gao, Zian Wang, Clement Fuji Tsang, Sameh Khamis, Or Litany, Sanja Fidler NeurIPS, 2021 project page / arXiv / code / video / bibtex DIB-R++ is a high-performant differentiable renderer which combines rasterization and ray-tracing together and supports advanced lighitng and material effects. We further embed it in deep learning and jointly predict geometry, texture, light and material from a single image. |

|
Yuxuan Zhang*, Wenzheng Chen*, Jun Gao, Huan Ling, Yinan Zhang, Antonio Torralba Sanja Fidler (* Equal contribution) ICLR, 2021 (Oral Presentation) project page / arXiv / code / video / bibtex We explore StyleGAN as a multi-view image generator and train inverse graphics from StyleGAN images. Once trained, the invere graphics model further helps disentangle and manipulate StyleGAN latent code from graphics knowledge. Our work was featured at NVIDIA GTC 2021 and has become an Omniverse product. |
|
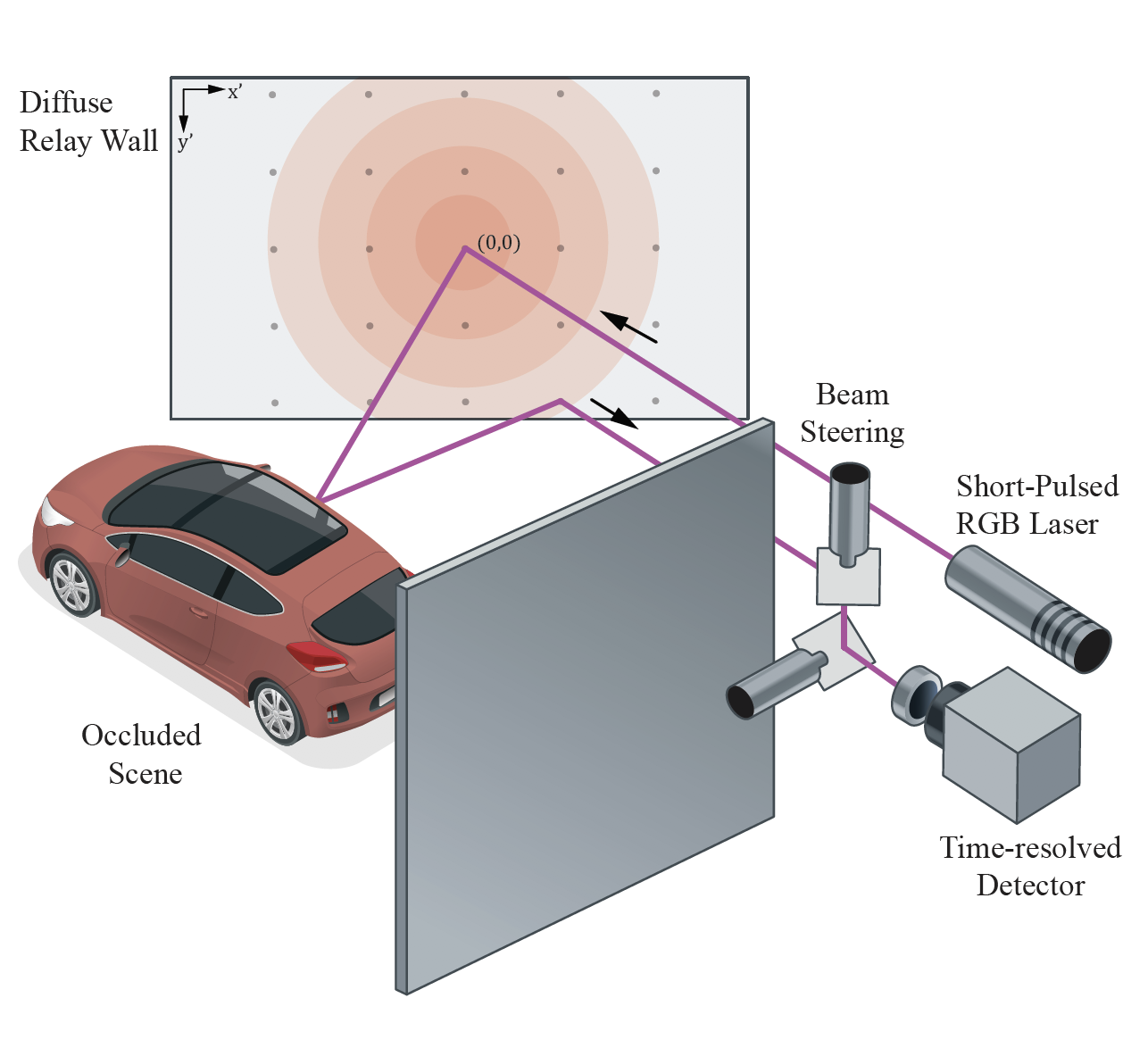
Wenzheng Chen*, Fangyin Wei*, Kyros Kutulakos, Szymon Rusinkiewicz, Felix Heide (* Equal contribution) SIGGRAPH Asia, 2020 project page / paper / code / bibtex / Art of Science Exhibition We propose to learn feature embeddings for non-line-of-sight imaging and recognition by propagating features through physical modules. |
|
Jun Gao, Wenzheng Chen, Tommy Xiang, Alec Jacobson, Morgan Mcguire, Sanja Fidler NeurIPS, 2020 project page / arXiv / code / video / bibtex We predict deformable tetrahedral meshes from images or point clouds, which support arbitrary topologies. We also design a differentiable renderer for tetrahedron, allowing 3D reconstrucion from 2D supervison only. |

|
Wenzheng Chen*, Parsa Mirdehghan*, Sanja Fidler, Kyros Kutulakos (* Equal contribution) CVPR, 2020 (ICCP 2021 Best Poster Award) project page / paper / code / video / bibtex We present optical SGD, a computational imaging technique that allows an active depth imaging system to automatically discover optimal illuminations & decoding. |

|
Wenzheng Chen, Jun Gao*, Huan Ling*, Edward J. Smith*, Jaakko Lehtinen, Alec Jacobson, Sanja Fidler (* Equal contribution) NeurIPS, 2019 project page / arXiv / code / bibtex / Two Minute Paper An interpolation-based 3D mesh differentiable renderer that supports vertex, vertex color, multiple lighting models, texture mapping and could be easily embedded in neural networks. |
|
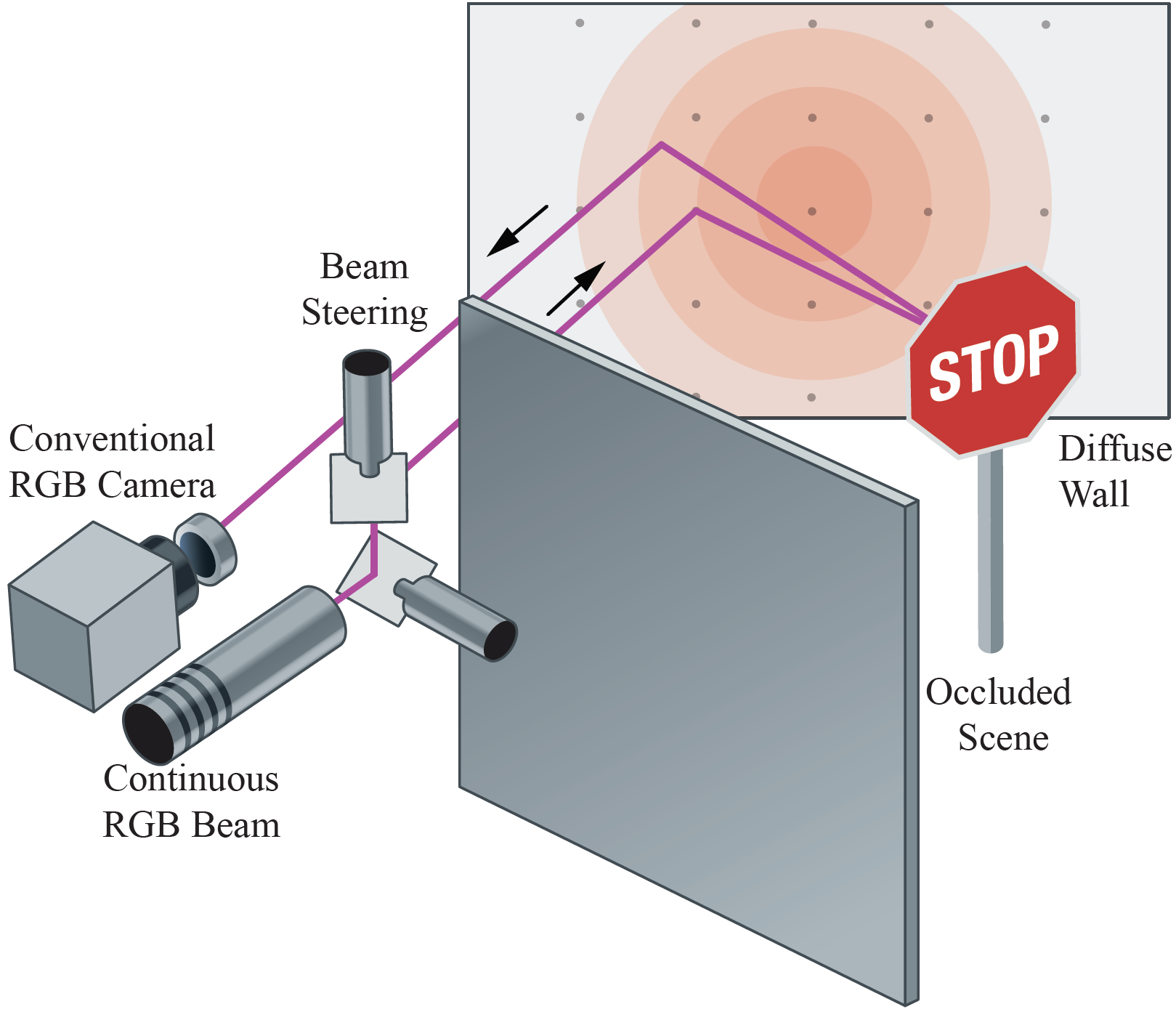
Wenzheng Chen, Simon Daneau, Fahim Mannan, Felix Heide CVPR, 2019 (Oral Presentation) project page / arXiv / code / bibtex We show hidden objects can be recovereed from conventional images instead of transient images. |

|
Huan Ling*, Jun Gao*, Amlan Kar, Wenzheng Chen, Sanja Fidler (* Equal contribution) CVPR, 2019 project page / arXiv / code / bibtex We predict object polygon contours from graph neural networks, where a novel 2D differentiable rendering loss is introduced. It renders a polygon countour into a segmentation mask and back propagates the loss to help optimize the polygon vertices. |
|
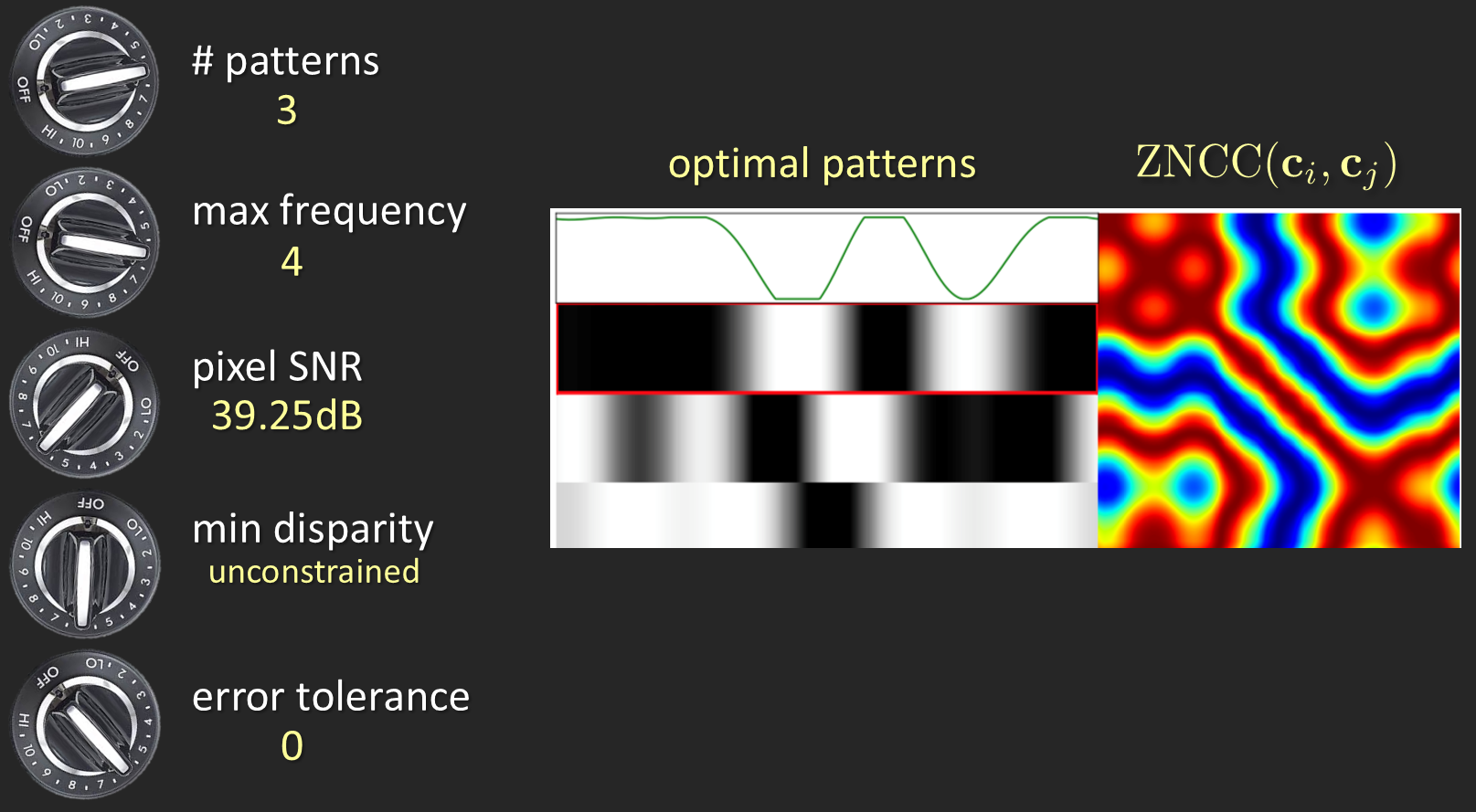
Parsa Mirdehghan, Wenzheng Chen, Kyros Kutulakos CVPR, 2018 (Spotlight Presentation) project page / paper / code / bibtex alacarte designs structured light patterns from a maching learning persepctive, where patterns are automatically optimized by minimizing the disparity error under any given imaging condition. |


|
Wenzheng Chen, Huan Wang, Yangyan Li, Hao Su, Zhenhua Wang, Changhe Tu, Dani Lischinski, Daniel Cohen-Or, Baoquan Chen 3DV, 2016 (Oral Presentation) project page / arXiv / code / bibtex 3D pose estimation from model trained with synthetic data and domain adaptation. |
|
Template adapted from Jon Barron. |